
Using YOLOv11 and FaaS with Fission for Automated Crack Detection in Infrastructure Projects

Municipalities and major utility companies face challenges in keeping their infrastructure up-to-date and well-maintained. Traditional monitoring methods rely on pilots and sensors to assess assets. Drones offer a more efficient alternative, enabling reproducible flight paths, high-resolution photography, and enhanced photogrammetry. However, significant challenges still remain, primarily in organizing and making accurate assessments of the large amounts of collected data. Machine learning can be leveraged to streamline this process, enabling efficient analysis and the extraction of meaningful insights.
Crack detection is crucial for maintaining the integrity of infrastructure such as bridges, roads, and buildings. Even small cracks can lead to major structural issues if left unchecked, with erosion, water damage, and environmental factors accelerating deterioration. Early identification of these cracks can prevent costly repairs and extend the lifespan of infrastructure.
In this blog series, we will explore Ultralytics' V11 You Only Look Once (YOLO) model to train a custom crack detection model. This model will then be deployed on Fission, a scalable and cost-efficient Functions as a Service (FaaS) platform. Fission, built on Kubernetes, enables seamless integration of machine learning models into workflows, offering elastic infrastructure that scales based on demand and supporting cross-cloud deployments. This approach will help infrastructure projects proactively address potential issues.
Caveat: There are areas for improvement in this setup. Currently, the classified image is fetched through a separate request, which must be routed to the same instance that handled the initial request to serve the file from its disk. A more robust solution would be to use an object storage service, allowing the server to return a
key or presignedUrl for the client to access the image directly. I fully appreciate that I could setup a NGINX container and proxy traffic to bucket (similar to the pattern for deploying the Vue application). However, this solution met my initial objectives to explore Fission and run a classification workload.
Part 1: The Crack Detection Problem & Model Training
Municipalities and utility companies face challenges in maintaining infrastructure due to the complexity and cost of monitoring large assets. Drone imagery offers a solution, but the manual processing of vast amounts of data remains a significant obstacle.
To overcome these challenges, I used Ultralytics' YOLO V11 model and trained it on a custom dataset of pavement cracks. The training was performed on a node within a self-hosted Proxmox cluster with the following specifications:
- Memory: 72GB
- CPU: 2 sockets, 8 cores (16 vCPUs)
- GPU: GeForce GTX 1080
🎓 Tutorial
Clone the pavement_cracks repository to get started. The current demo-site is running the general-detection model, while the segmentation model is still a work-in-progress but will be completed soon.
The general-detection model is designed to classify four types of pavement cracks:
- Longitudinal Cracks
- Transverse Cracks
- Obliquely Oriented Cracks
- Alligator Cracks
To train this model first install the necessary packages into a virtual environment.
pyenv virtualenv 3.12.3 pavement-cracks
pyenv activate pavement-cracks
pip install -r requirements.txtFind a suitable dataset that that has a good balance of images. My test, train, and validate sets had 129, 1111, and 149 respectively. The paths to these images should be populated in the data.general_detection.yaml .
train: <path>
val: <path>
test: <path>
nc: 4
# 0: LC - Longitudinal Crack
# 1: TC - Transverse Crack
# 2: OC - Obliquely Oriented Crack
# 3: AC - Alligator Cracks
names: ['0', '1', '2', '3']Confirm that your GPU and NVIDIA drivers are correctly installed and configured:
lspci
#....
00:10.0 VGA compatible controller: NVIDIA Corporation GP104 [GeForce GTX 1080] (rev a1)
nvidia-smi
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.05 Driver Version: 560.35.05 CUDA Version: 12.6 |Consider using Weights and Biases to monitor training progress. It provides a more enhanced experience than Tensorboard, facilitating the identification of trends across training cycles and helping to improve reproducibility as configurations change. If you do not have a Weights and Biases account, comment out the respective lines in train.py.
For this project, I used yolov11n.pt - the smallest of the Yolo models based on its nano architecture with fewer parameters. The results discussed below (particularly the recall thresholds) would likely improve with larger models.
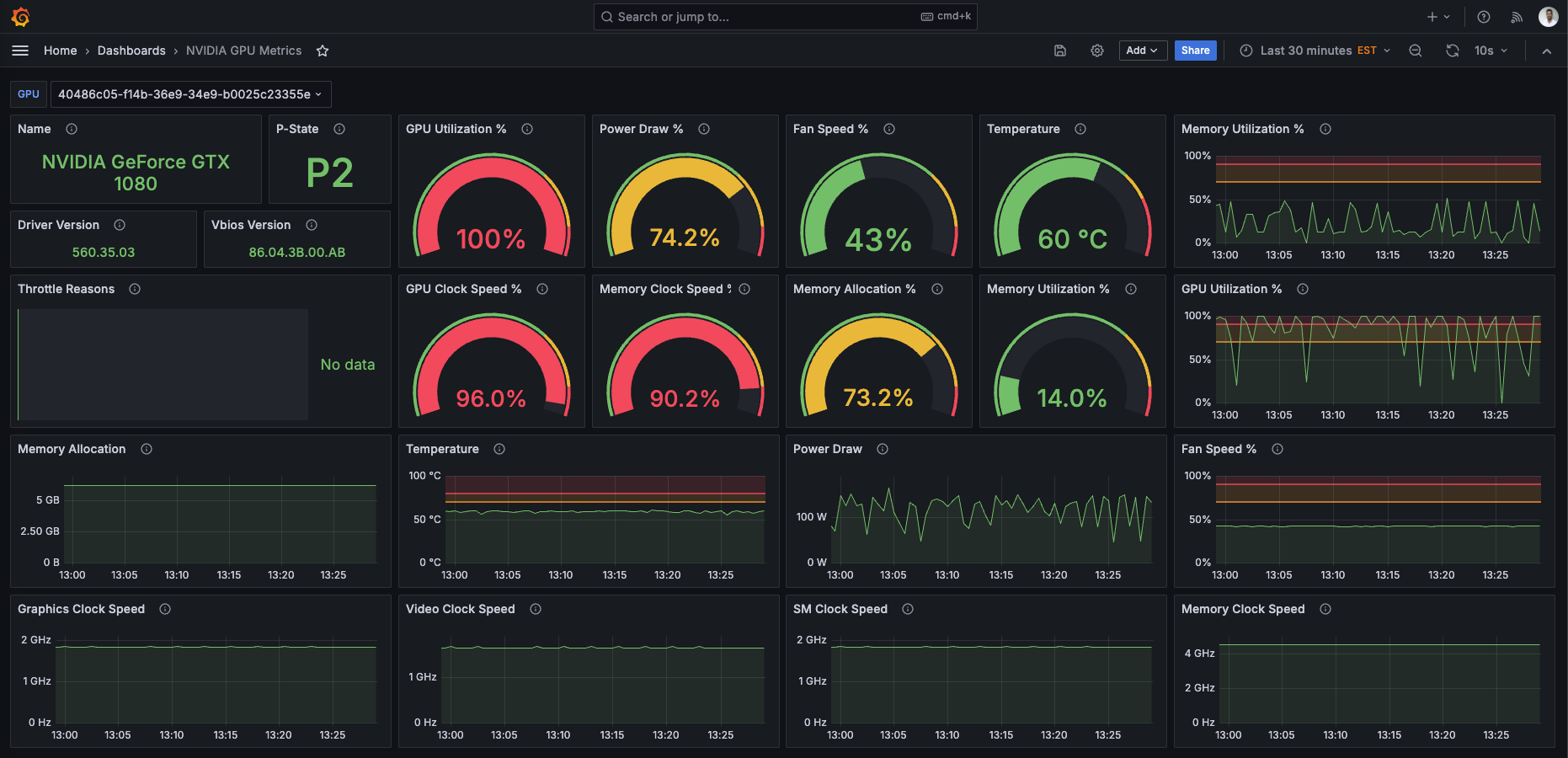
GPU Monitoring
While experimenting with machine learning, I wanted to better understand the capacity of my GTX 1080. I found a Prometheus exporter, installed it on the host, and added a target to my Prometheus config:
- job_name: "nvidia_gpu"
# scrape_interval: 30s
static_configs:
- targets: [
"<node>:9835", # train-server
]This setup allowed me to create a dashboard for monitoring.
Analysis of the Pavement Crack Training
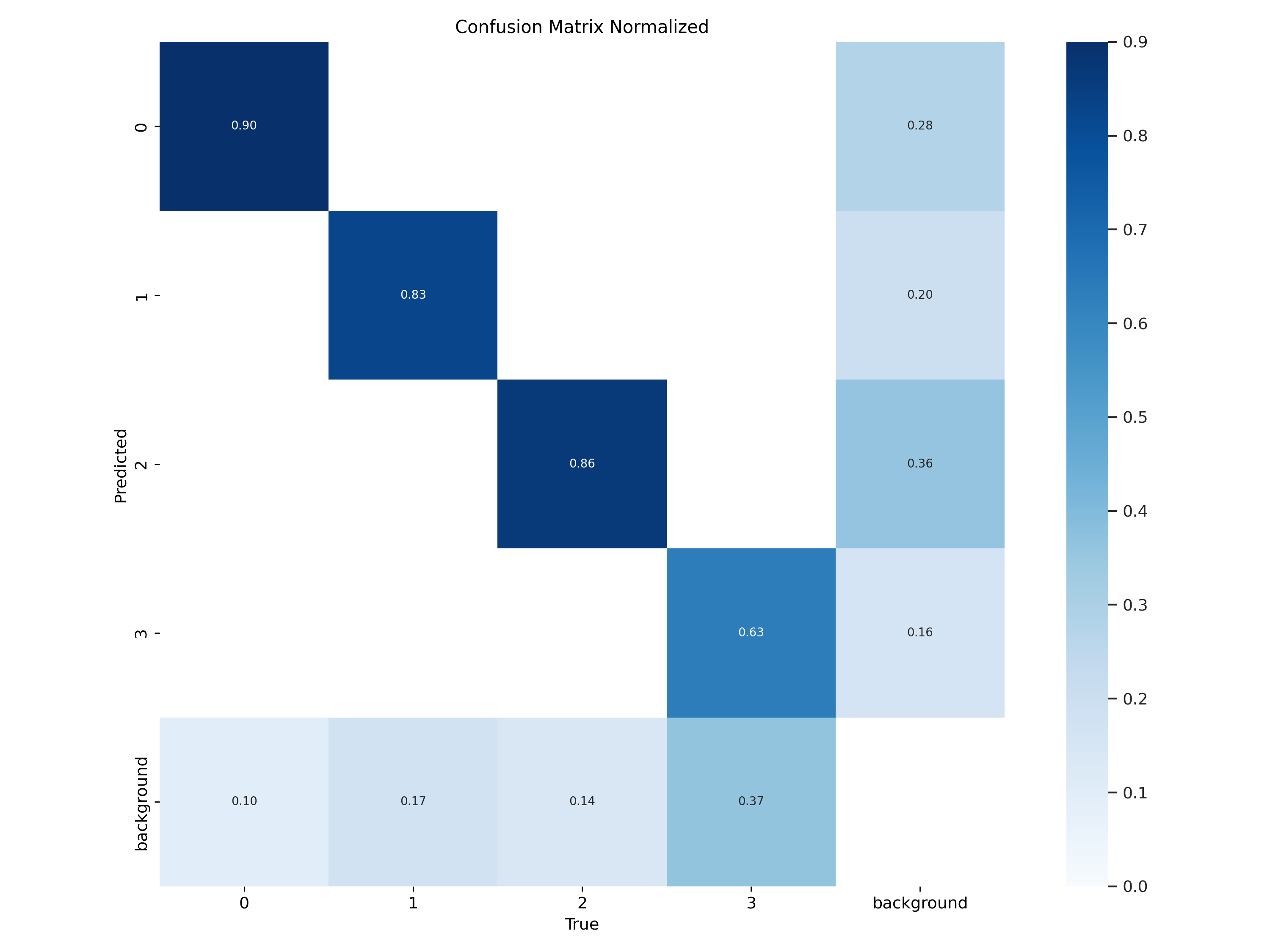
The confusion matrix shows strong predictive performance for classes 0 (Longitudinal Cracks), 1 (Transverse Cracks), and 2 (Oblique Oriented Cracks) with high accuracy rates of 90%, 83%, and 86% respectively, indicated by the dark blue diagonal elements. Class 3 (Alligator Cracks) demonstrates moderate performance with 63% accuracy. The model shows challenges with the "background" class, which is expected since this class was removed from the training data, leaving the model with no knowledge of this category.
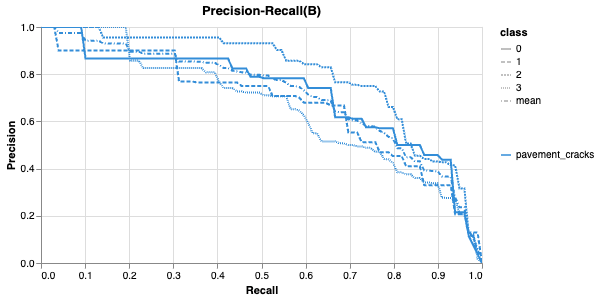
The Precision-Recall curve shows the model maintains high precision (>80%) up to 50% recall, demonstrating good confidence thresholds for obvious predictions. There's a sharp drop in precision when recall exceeds 90%, suggesting the model struggles with the most difficult examples. This performance could potentially be improved by using a different YOLO model with more parameters.
Artifacts
A best.pt model should be created after each epoch, along with a last.pt model. The .pt extension stands for "Pre-Trained." At the end of the training, copy the best.pt model to ./app/server for use at the API layer. Additionally, the .pt file can be exported to an ONNX format for improved interoperability and performance—an option I plan to explore further. However, for this project, I’ve kept the model in its original format. This pre-trained model will be loaded by Fission, a Function-as-a-Service (FaaS) framework that runs on Kubernetes.
Functions-as-a-Service
Function as a Service (FaaS) is a cloud computing model that allows individual functions to execute in response to events. It’s a subset of the "serverless" paradigm, where application-level code runs based on incoming requests or events. Services like AWS Lambda and Google Cloud Functions are examples of FaaS offerings.
FaaS is often described, by those offering to manage the complexity for you, for its simplicity. Developers don’t need to manage the underlying infrastructure and they can scale with demand. However, this is not to say they do not introduce their own complexity. For better or worse, FaaS encourages the modularization of code and the shift to microservices.
My interest in starting this project stemmed from FaaS scalability. I wanted to test whether the application could scale to meet demand and, during off-peak hours, scale down to zero instances, effectively reducing the cost of running the application. I also was not keen on running the application on a public cloud. I have a moderately sized homelab with a Proxmox cluster, and I wanted to explore whether I could implement a FaaS framework on Kubernetes.
Function-as-a-Service (FaaS) & Kubernetes with Fission
Fission is a Functions as a Service (FaaS) framework built on Kubernetes, enabling the deployment of services similar to traditional serverless offerings. It supports hybrid-cloud, public-cloud, and mixed environments, making it ideal for organizations with diverse infrastructure needs that still want to take advantage of elastic infrastructure. Since Fission is a Kubernetes framework, it is not tied to a single public cloud and can seamlessly work across multiple cloud providers, enabling the deployment of functions in a multi-cloud setup.

Fission includes several custom resource definitions (CRDs), such as Functions, HTTPTrigger (a route), and MessageQueueTrigger. As you'll see in the deployment directory of the repository, this project primarily focuses on Functions and HTTPTrigger. Although the framework aims to simplify Kubernetes concepts through a CLI tool, I found it unhelpful for my needs. Integrating it with my internal CI/CD system made configuring and deploying functions cumbersome, and I ended up avoiding it.
📓 Hot and Cold Starts with FaaS in General
When working with FaaS, one of the biggest performance bottlenecks can be the time spent loading the application code, such as packages or other external resources. Effectively, the application's codebase needs to be downloaded as an archive file from S3 or other object storage solution, or a container's image must be pulled from a registry. Both of these are network-bound, and do not benefit from increased compute power. Rather they are bound by the network interface card, networking speeds, and likely the storage device and bus that the codebase is being written to on the executor
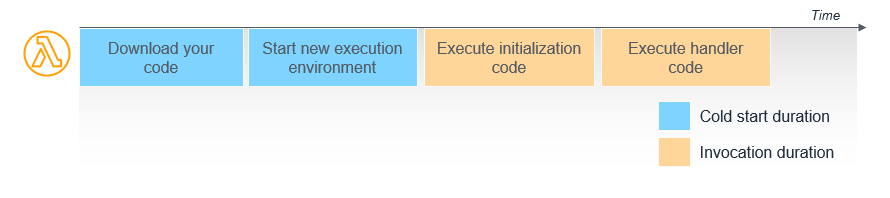
There are several ways to reduce cold start duration. One approach is to modularize the codebase, minimizing the function’s size and dependencies. AWS also offers "Provisioned Concurrency," which keeps a specified number of function instances initialized and ready to respond.
While this improves performance, it introduces a paradox: serverless computing was designed to eliminate the need for always-on infrastructure, yet solutions like Provisioned Concurrency reintroduce pre-warmed instances, blurring the line between serverless and traditional hosting. This shift moves the paradigm toward a model where latency, rather than pure on-demand execution, becomes the driving metric.
The Anatomy of a Fission Function
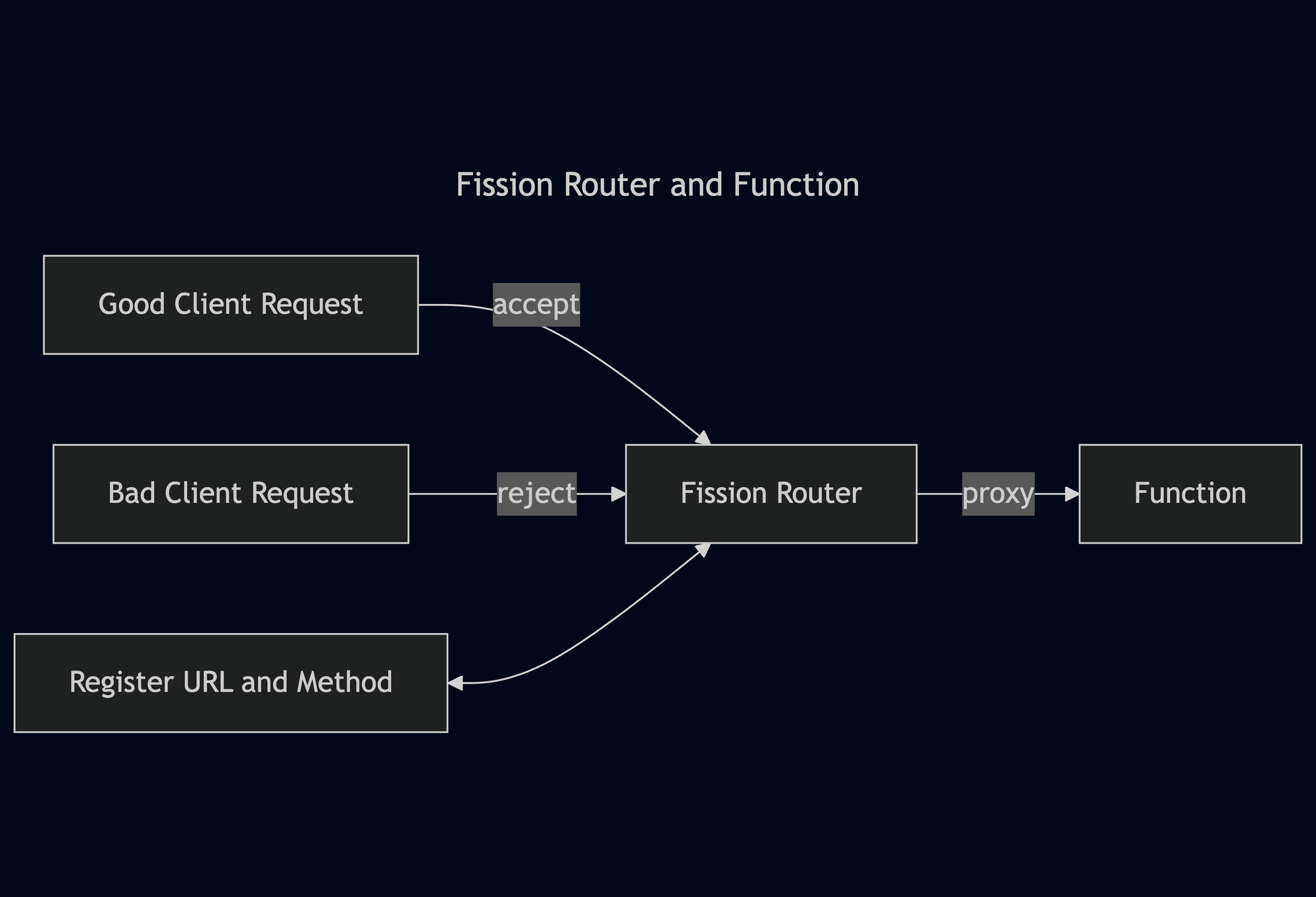
Fission functions are executed by the router, which receives incoming events. The router is the only stateless component and is responsible for forwarding HTTP requests to function pods.
First, the router checks its cache for an existing function service record. If there is a cache miss, it requests a function service from the executor and holds the request until the service is ready. The executor retrieves function details from the CRD and invokes the function. The PoolManager then selects a generic pod and converts it into a function pod. Once ready, the function pod’s address is returned to the router, which forwards the request to the function.
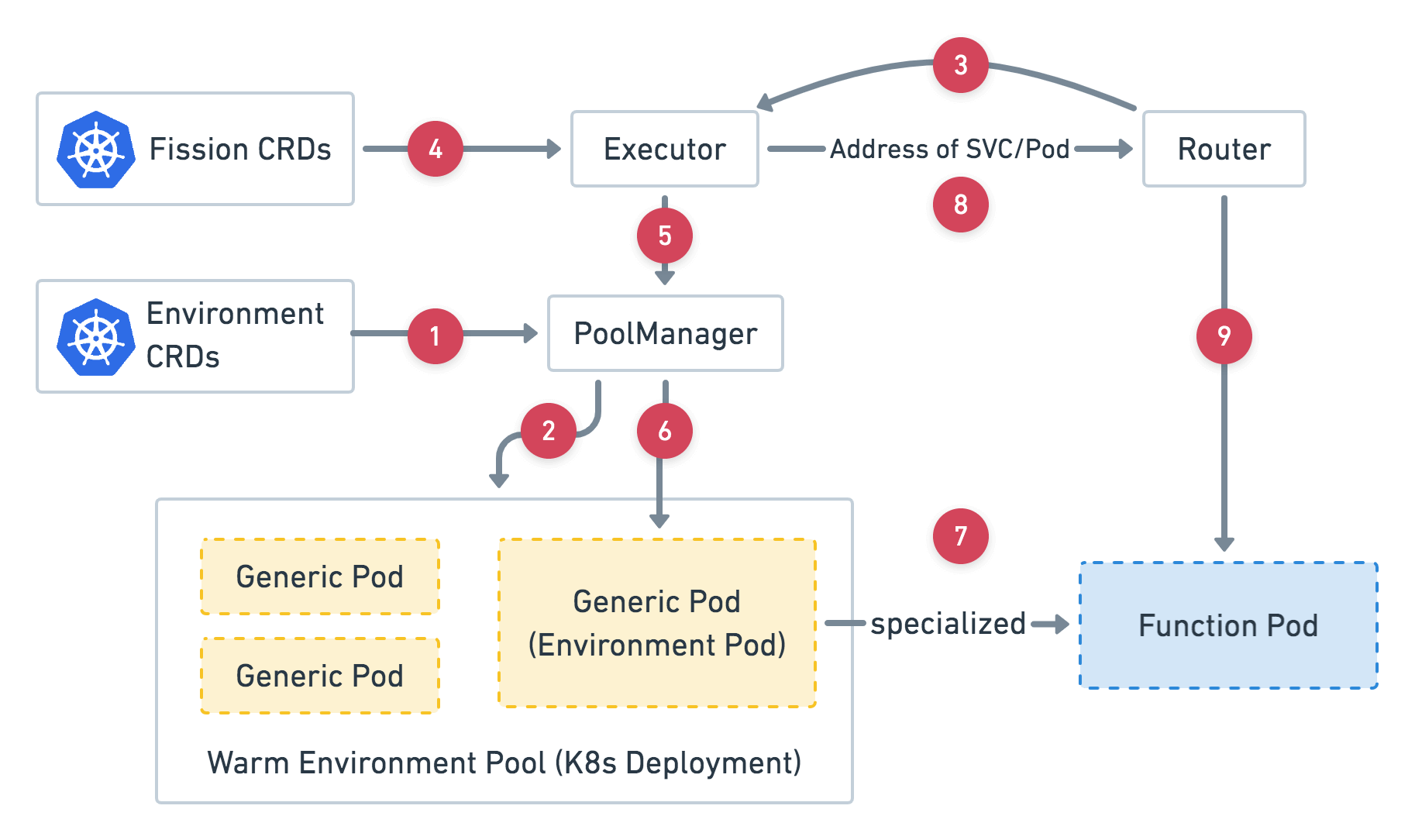
This workflow supports applications running either a binary or an archived codebase. In this project, the model's package size was around 3GB, significantly increasing the overall package size. To address this, I containerized the project and hosted the image in my private registry.
Fission in Application
Fission's documentation recommends using their CLI to create functions. However, this approach didn't align with my CI/CD workflow, and I preferred using a manifest file for more control and transparency.
apiVersion: fission.io/v1
kind: Function
metadata:
creationTimestamp: null
name: cracks
namespace: default
spec:
InvokeStrategy:
ExecutionStrategy:
ExecutorType: container
MaxScale: 5 <-- Maximum number of functions to scale
MinScale: 0 <-- Minimum number of function to scale
SpecializationTimeout: 120
TargetCPUPercent: 0
StrategyType: execution
environment:
name: ""
namespace: ""
functionTimeout: 60
idletimeout: 120
package:
packageref:
name: ""
namespace: ""
podspec:
containers:
- image: registry.sachasmart.com/pavement_cracks:amd-v10 <-- registry
imagePullPolicy: IfNotPresent
name: cracks
ports:
- containerPort: 8000
name: http-env
resources: {}
env:
- name: ENV
value: "debug"
- name: ALLOWED_ORIGINS <-- cors
value: "https://pavement-cracks.sachasmart.com"
imagePullSecrets:
- name: registry-secret
terminationGracePeriodSeconds: 0
resources: {}The most notable attributes of the manifest are found in the InvokeStrategy. Since the ExecutorType is set to container, when a request is sent from the router to the executor, it will check the function's CRD and use the container executor type to create the function.
The MaxScale and MinScale properties control horizontal scaling. MaxScale defines the maximum number of instances the router can scale to meet demand, while MinScale sets the minimum number of instances that must be running at all times. Setting MinScale to a value greater than zero helps reduce request latency by ensuring a "warm" instance of the function is always available.
The function is controlled by the HTTPtrigger, with the following spec:
apiVersion: fission.io/v1
kind: HTTPTrigger
metadata:
generation: 1
name: cracks
namespace: default
spec:
createingress: false
functionref:
functionweights: null
name: cracks <--- function to execute
type: name
host: ""
ingressconfig:
annotations: null
host: '*'
path: /cracks
tls: ""
method: ""
methods:
- GET
- POST
- OPTIONS
prefix: ""
relativeurl: /cracksThe HTTPTrigger spec defines the function name to be executed when it receives GET, POST, or OPTIONS HTTP requests at the /cracks endpoint.
Structure of the Application (Fast API)
This crack classification model follows a monolithic design, utilizing FastAPI with GET and POST routes. However, instead of defining separate route handlers, the implementation determines the behaviour based on the HTTP method within a single function. You’ll notice:
@app.api_route("/", methods=["GET", "POST"])
if request.method == "POST":
....
if request.method == "GET":
....
----
# Compared to traditional approaches
@app.get("/")
async def get_route():
...
@app.post("/")
async def post_route():
....
I wrote this as a monolithic application to explore running FaaS on Kubernetes and deploying a test application. I recommend further modularizing functions into their respective endpoints for better maintainability.
Small Note on the Vue Application
The Vue Single Page Application (SPA), which enables users to drag and drop crack images, is served from a self-hosted MinIO bucket.
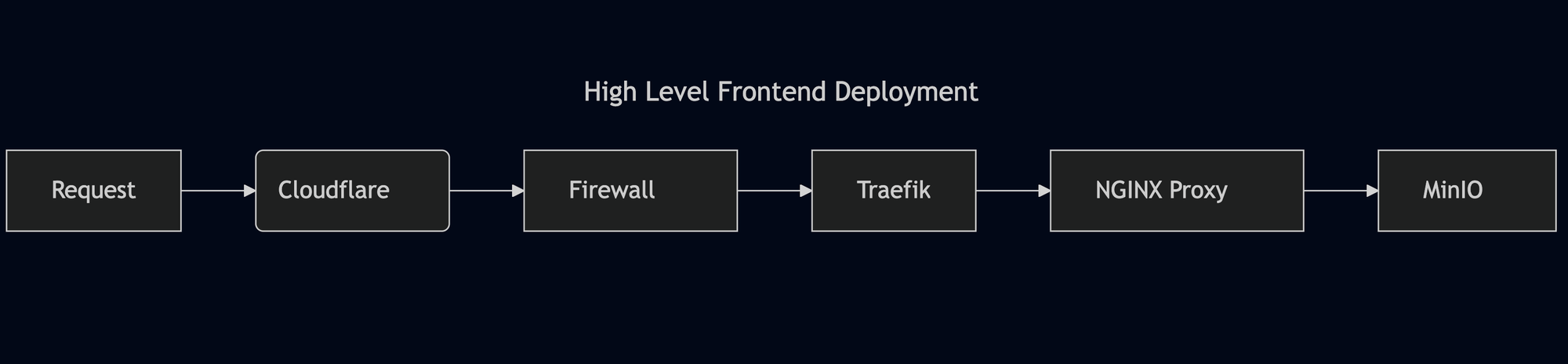
A Kubernetes deployment runs an NGINX container that proxies requests, which are routed through a Traefik reverse proxy defined by an IngressRoute. Traefik operates behind Cloudflare, which obscures my homelab's IP address. In fact, this blog is entirely self-hosted and served from my home office!
If you are interested in running a similar configuration, the NGINX configuration can be found here, and the Traefik configuration is available here.
Conclusion
Using Fission offers developers greater flexibility in application development by enabling seamless scaling, reduced infrastructure management, and efficient resource utilization. It allows for those running hybrid or on-premise clouds still have elastic infrastructure - even run this in your homelab!
